March 27, 2026
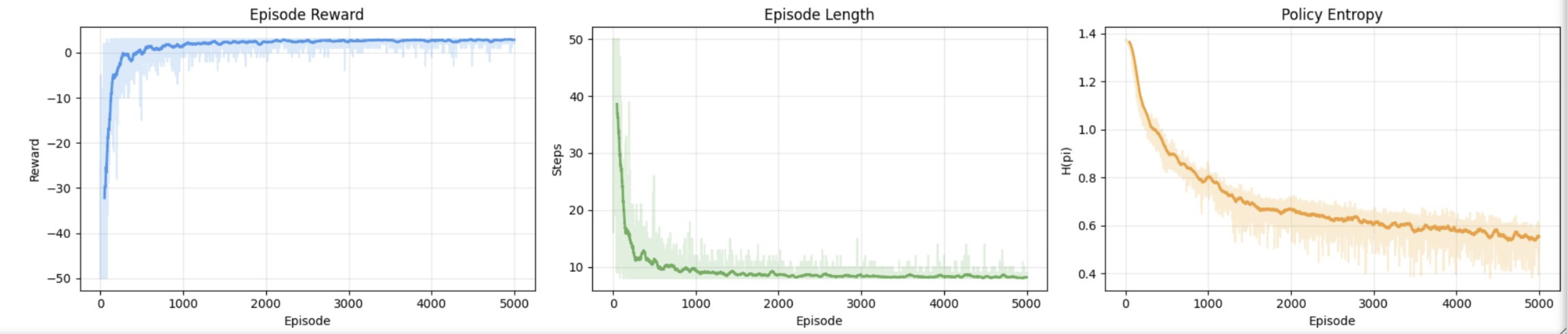
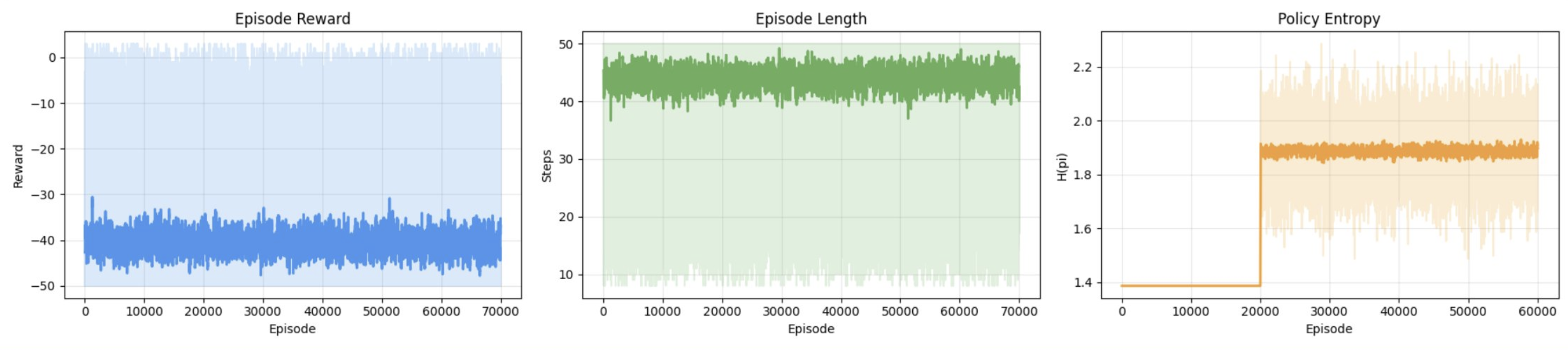
In this experiment, we play around with a very simple algorithm on a very simple environment. This is a good starting point for RL research: train a neural net with the policy gradient method, experimenting with different experimental setups, such as varying the size of the model, training episode length, and the size of the environment/grid.