x86 Assembly Notes
By: Rohan Sikand
Table of contents:
We will cover the x86 assembly language over the next four lectures (lectures 10-13).
Introduction to x86 and Moving Data
Lecture 10 notes.
So we know that everything is represented in bits. But what about the literal C program source code itself? Yep! That is also converted into bits.
- GCC is a compiler that converts human-readable code into machine-level instructions.
- This machine code is all in 1s and 0s so that the computer can interpret it.
- However, there is something called assembly which represents the machine code in a human-readable fashion.
- So basically, in C, you first write your program in a
.cfile. Then, you use the GCC compiler to compile the program. This produces a binary executable which is what you then run to get your output. This binary executable is the C program in machine-level code.- Now, there is an intermediary called assembly which basically translates these instructions into a human read-able format. We will learn this language.
Viewing assembly
In your terminal window, compile your C program using make which should produce the executable which is binary machine code. Now to view this executable in assembly, type:
objdump -d <executable_name>Let us now learn how to interpret the assembly representation. We will break down what is outputted by objdump. First, here is the C source of the program we are looking at.
// c code of assembly below
int sum_array(int arr[], int nelems) {
int sum = 0;
for (int i = 0; i < nelems; i++) {
sum += arr[i];
}
return sum;
}Here is an example of assembly for the above code:

Each line represents an instruction.
Dissecting this down, we have the function name (instructions are divided into sub-blocks based on function calls):
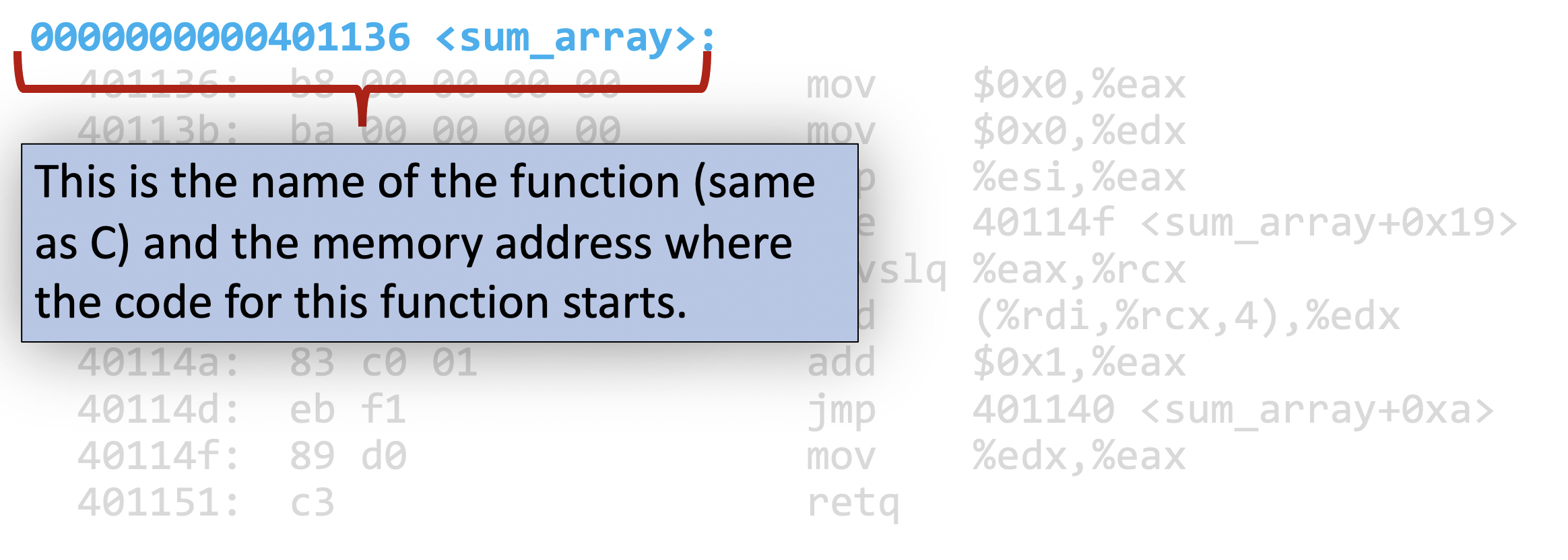
we also have the memory addresses of each instruction:

and the machine code for each instruction:

then finally we have the human-readable version of the machine code for each instruction (i.e. the actual assembly)

Instructions
The fundamental unit of assembly is an instruction which is represented on the right hand side of each line in the breakdown above. Let us interpret the structure of each assembly instruction.
We have the opcode which is the name of the operation (there are different types of operations which we will explore):

We can also have arguments:

We can break down each argument here. Anything prefixed with a $ is a constant numerical value (also called an immediate value):

and anything prefixed with a % is something called a register which is something we will introduce next.

Registers
- Machine code representations are dependent on the processor they are running on. That is, assembly is different for each processor which is why you cannot run some Intel x86 apps on the new M1 macs since it uses a different assembly instruction set. In this class, we will use the x86 instruction set. The reason why assembly is dependent on the processor is because of registers.
- We now introduce registers which are a fundamental concept in assembly.
- In the processor, there are 16 different registers:
- But what exactly is a register?
- Like a scratch pad for the processor. That is, it loads data into and out of these registers when it needs to perform some sort of operation on such data.
- Note that registers are not located in memory and are 64 bits big inside the processor itself.
- Side note: remember how some computers used to be 32 or 64 bit? This is where this originated from!
- Important note: some computers have 32-bit registers and thus their registers are prefixed with
einstead ofr(%eipinstead of%rip).- That is, if a register is prefixed with an
r, you are referring to the 64-bit version of the register whereas if you the register is prefixed with ane, you are referring to the 32-bit version of the register. So%eipand%riprefer to the same register but just different amounts of that register.- When you disassemble C source, you'll see both of these show up from time to time. When C operates with a data type such as
long, it takes up 64 bits in the register and if it is just a regularintand the register name is prefixed with anr, then the register is 32 bits and prefixed with ane.
- When you disassemble C source, you'll see both of these show up from time to time. When C operates with a data type such as
- That is, if a register is prefixed with an
- To make this more concrete: look at the following picture:

- The entire register is 64-bits but sometimes you don't need the higher order bits. Thus, you can access the lower order bits using the
eprefix. Funnily enough, you can even access just the lower16and8bits as well but we don't need to get into those for our purposes.
- The entire register is 64-bits but sometimes you don't need the higher order bits. Thus, you can access the lower order bits using the
- Important note: some computers have 32-bit registers and thus their registers are prefixed with
- Side note: remember how some computers used to be 32 or 64 bit? This is where this originated from!
- In addition to local variable values, registers can also hold function return values and parameters among other things.
- Registers are important since they are extremely fast memory and also because most of the assembly instructions deal with moving data in and out of registers.
- Examples include operations such as adding two numbers in a register, move to memory and move from memory.
- Specifically, this is the level of abstraction we will deal with. Common assembly code includes things like moving data into one register than copying the data at that register to another memory location. Things like that. Thus, it is vital to understand registers and what they do.
- In furthering our understanding of the level of abstraction of assembly, take the following one line of C code:
int sum = x + y;- In assembly, instead of it being just one line, it is actually 4. First, we copy x into register 1. Then, we copy y into register 2. Then, add the two registers. Finally, we write register 1 to memory.
- You see how we use registers for everything? This reduces the layers of abstraction but adds more complexity.
- There are certain registers which have special meanings (i.e. the program counter).
- This is important in understanding the motivation for why we need registers in the first place. As a brief example (which we will learn about more in the future), is the program counter register. This memory slot stores the address of the next instruction to execute. So you can think of some registers in the meta sense in that they hold things about the instructions themselves which is needed to execute the flow correctly.
A register that is alphabetic is a special register whereas numeric named ones are just regular registers.
- Some registers are named numerically while others are named alphabetically. This is simply a consequence of legacy as in the early days there were only 8 registers instead of 16. So to differentiate it, the newer ones were named numerically since the older 8 were named alphabetically.
- The x86 architecture set was designed by Intel back in 1978. It was originally designed with 16-bit registers but soon it extended to 32 and now 64-bit registers. Because of this, Intel made unique design decisions to ensure backwards compatibility. As a consequence of this however, this backwards compatibility is evident in register names and things like that.
The register layer of abstraction - if you think about it, in order to convert a high-level program such as a C source into 0s and 1s, all of the functionalities must be converted into a linear and atomic sequence. Atomic meaning each piece of functionality in the program itself must be broken down into the lowest possible level—the fundamental unit, which is a simple operation (such as "add two numbers"). To accomplish this, we need some form of scratch space to store things like the result of an operation for use later (i.e. scratch paper). That is exactly what registers provide for us. This is the register layer of abstraction.
Operations
Now that we have a fundamental understanding of instructions and registers, let us put them to use. We introduce some fundamental operations here. First up is mov. We then generalize the form of each operand in each instruction.
mov
Let us now introduce our first operation.
- We can think of assembly as the programming language of the machine itself. In that sense, an operation/instruction is like a function in assembly.
mov: assembly instruction that copies bytes from one place to another. - You can draw a parallel to the assignment operator (
=) that we have in C.
- Note: the order is
src, dest(opposite of=).
The src and dest can be one of:
- Immediate constant (only
srccan be this obviously).
- Register
- RAM memory location (can't both be this in one operation though).
- That is, you cannot do memory-to-memory transfer with a single instruction (like
memcpy).
- That is, you cannot do memory-to-memory transfer with a single instruction (like
So in other words, you have five possible combinations:

Example:
mov %rbx,_____Operand forms
We now introduce some neat tricks we can use to do things like pointer dereferencing and arithmetic at the assembly level.
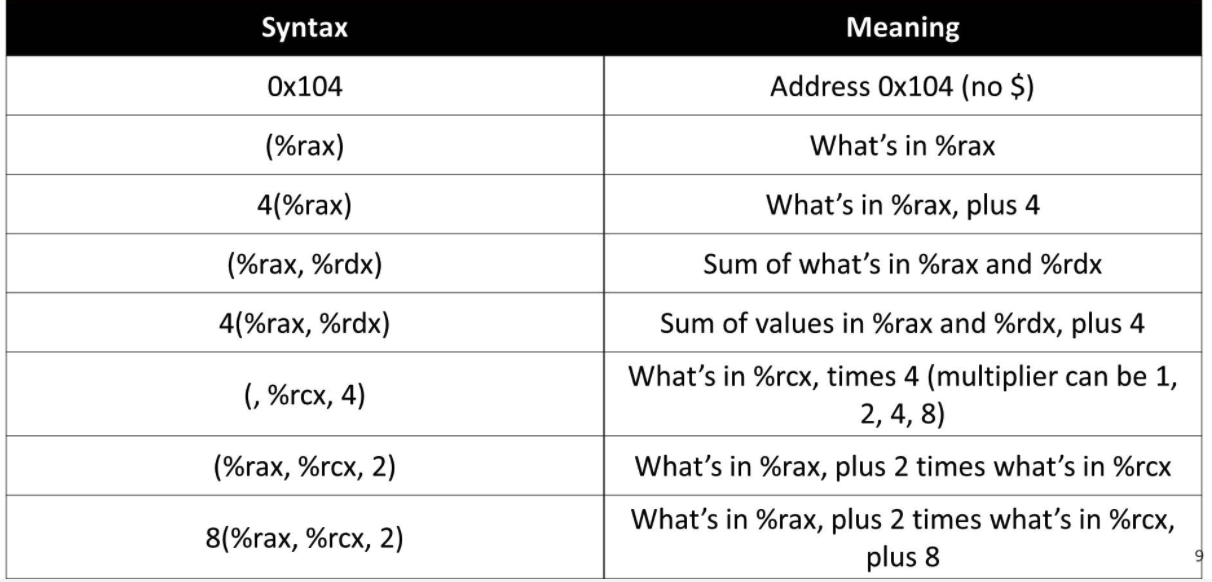
We will see a lot of common patterns in assembly instructions that represent certain forms. Here, we introduce some useful forms we will work with (and we use mov to illustrate such forms):
- Indirect: If we wrap the instruction in parentheses, we are in some ways "deferencing" it:
mov (%rbx),_____ Example
Here is a small little example of C to assembly that uses pointer dereferencing.

- Base + displacement: Usefully, we can harness some syntax to mirror arithmetic. Here we add ten to the address:
- As per precedence, the calculation happens first and then the dereferencing.
mov 0x10(%rax),_________- Indexed: sums up the values in the parentheses:
mov (%rax,%rdx),__________We can even combine them. In general, we have the following form:
Imm(rb, ri) is equivalent to address Imm + R[rb] + R[ri]
As a principle, if you think about it, everything above is modeled by the above form. For example, if you have no immediate before (i.e. no displacement), then the displacement is really just 0 in the above form. In other words, you should dissect and construct forms based on the above form and not really based on the operational principles themselves.
- Note that everything is in base 16.
- This is very important to note.
Another way of thinking about the above form is that it is kind of like array indexing. You have your displacement to get to the certain address of the array. Then, you have your start index (which is the bit width of an element) and go up until you have the element that you want.
More forms
We now introduce another form:
- Scaled Indexed: multiplication
mov (,%rdx,4),______- You might be thinking this looks similar to the summation form above. And it does, but the difference is that the scaling factor is hardcoded and is inside the parentheses.
We have introduced a lot of forms, but the general form is indeed:
Imm(rb,ri,s) = Imm + R[rb] + R[ri]*s
- Another interesting point to note is that these forms mirror a lot of C operations (such as array indexing). So to improve your translation skills, it is good to understand these forms.
Here is a nice chart:
Assembly: Arithmetic and Logic
Lecture 11 notes.
We will now dive deeper into our study of assembly and learn about how how to perform arithmetic and logical operations in assembly.
Note that in our study of assembly, our general perspective is to learn how to read assembly and understand the C code that generated it rather than write assembly from scratch.
Data and register sizes
We will introduce new terminology in terms of bytes that we will work with in assembly. We have:
- A byte is 1 byte.
- A word is 2 bytes.
- A double word is 4 bytes.
- A quad word is 8 bytes.
This is useful stuff to know when analyzing assembly instructions since assembly instructions can have suffixes to refer to these sizes:
bmeans byte, referring to 1 bytes.
wmeans word, referring to 2 bytes.
lmeans double word, referring to 4 bytes.
qmeans quad word, referring to 8 bytes.
Subsets of registers
In addition to different sizes of data, there are different sizes of registers as well. These have different naming conventions and are sort of like nesting dolls. Example:

- Due to backwards compatibility.
Register responsibilities
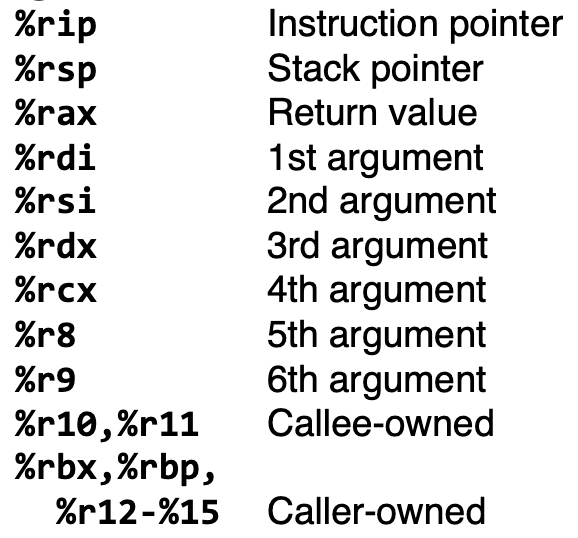
Some registers take on special responsibilities during program execution:
%raxstores the return value
%rdistores the first parameter to a function
%rsistores the second parameter to a function
%rdxstores the third parameter to a function
%ripstores the address of the next instruction to execute
%rspstores the address of the current top of the stack
mov variants
Like we saw with the registers, the instruction opcodes can also be suffixed that specifies the size of the data to move:
movb
movw
movl
movq
For example, movl moves 4 bytes.
A couple funky things/additions to note:
movlsets higher-order 32 bits to 0.
- For some reason, you cannot use
movqto copy an immediate constant of 64 bits into a register. Thus, you must usemovabsq.
- If we want to, say, copy a smaller source into a larger destination, we can use
movzandmovswheremovzfills remaining higher-order bits with 0 andmovssign-extends higher-order bits.- You can even suffix these (e.g.
movsbw). See table in lecture slides.
- A limitation of these is that the source must be from memory or a register, and the destination is a register.
- You can even suffix these (e.g.
cltqis like amovswhich automatically sign-extends a 32-bit register to a 64-bit register.
lea
We now introduce a new instruction for arithmetic operations.
- Syntactically like
mov, but quite different in reality.
lea: The lea instruction copies an “effective address” from one place to another. Unlike mov, which copies data at the address src to the destination, lea copies the value of src itself (for example, an address rather than dereferencing) to the destination.- The syntax for the destinations is the same as
mov. The difference is how it handles the src.
leaismovwithout the dereferencing.
Examples:

Unlike mov, which copies data at the address src to the destination, lea copies the value of src itself to the destination.
You might think... why don't we just use mov without dereferencing using parentheses. Well, recall that only one of the src or dest can be a register... not both. Thus, we can use lea instead. Another motivation for lea is that what happens if you want to use an operand form (e.g. scaling factor, addition) but do not want to dereference? You can't. So you must use lea.
Logical and arithmetic operations
So far we have been dealing with binary instructions. We also have unary instructions that operate with only one operand:

We also have more binary operations:
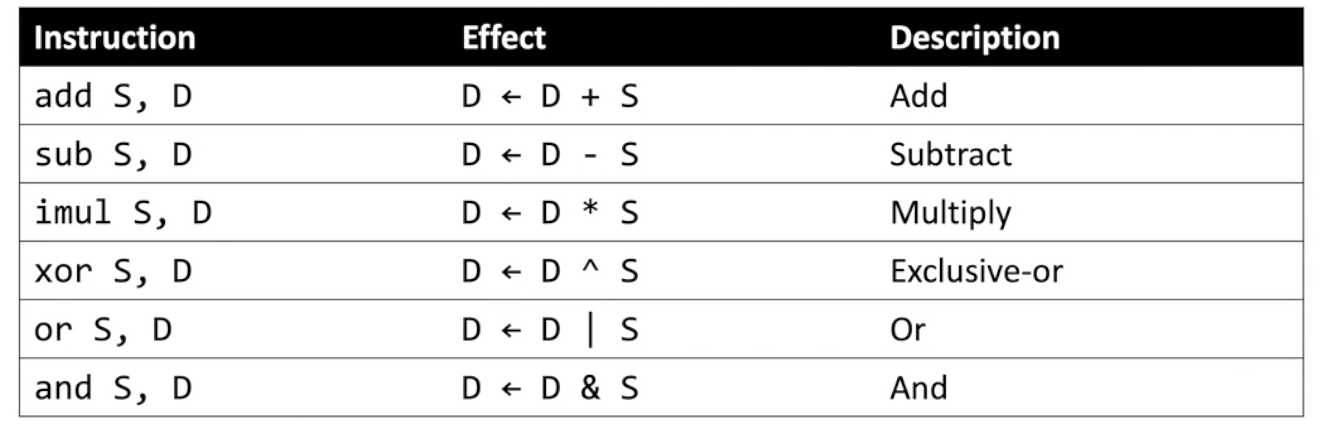
mov). Also notice the bitwise operations. > 64-bit arithmetic
Here is a thought: if registers are only 64 bits big... how do we multiply two 64 bit numbers together? That would be larger than 64 bits but our registers cap out at 64 bits. The answer is:
imul: will truncate result to 64 bits.
- If you specify one operand, it multiplies that by
%rax, and splits the product across 2 registers. It puts the high-order 64 bits in%rdxand the low-order 64 bits in%rax.
Division
Division is similar (can do 128 bit/64 bit number):
- dividend / divisor = quotient + remainder
- The high-order 64 bits of the dividend are in
%rdx, and the low-order 64 bits are in%rax.- This is an assumption meaning the computer will assume those values have already been moved and stored there.
- The divisor is then the operand to the instruction.
- The quotient is stored in
%rax, and the remainder in%rdx.
Note: this is actually how division is done even with < 64 bit numbers. You must sign extend the higher order bits first to fill in%rdxin that case. For this, usecqto.
Bit shifting
- The following bit shifting instructions have two operands: the shift amount
kand the destination to shift,D.
kcan be either an immediate value, or the byte register%cl(and only that register though!)
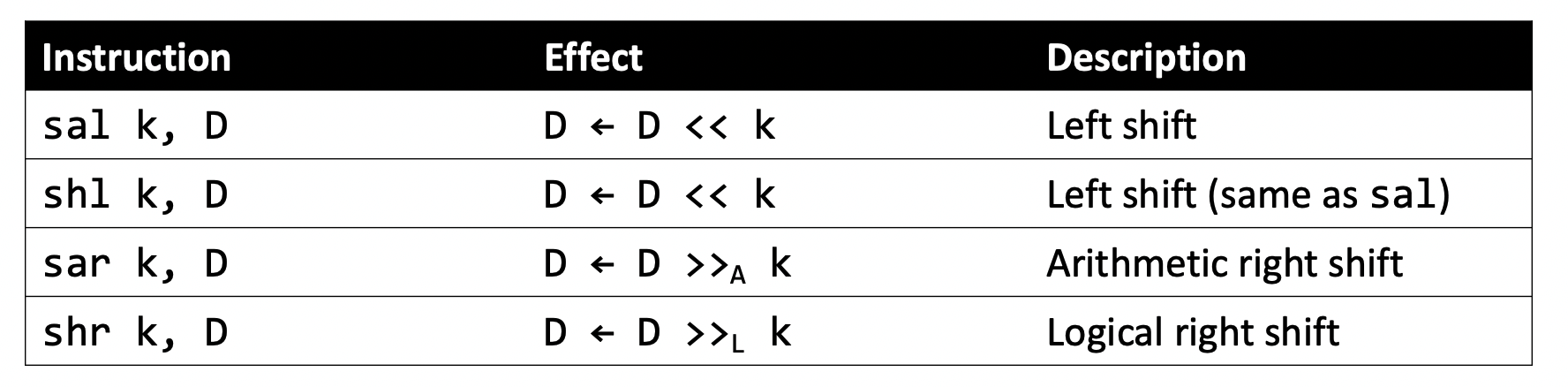
- Note that the
%clrule is quite confusing.
Reverse Engineering
- Our goal is to be able to understand what code generated what assembly instructions.
- godbolt.org is a useful website that has a Compiler Explorer where you can type in C code and it will give you x86 assembly back. Quick and easy playground.
Assembly: Control Flow
Lecture 12 Notes.
We will now talk about control flow. This is a very meta topic.
- Who controls the instructions? Who controls which instruction to execute next? The answer:
%rip: register that stores the address of the next assembly instruction to execute. So, as you will see, we use this register for things like if-statements and loops.
- Without control flow,
%ripwill be updated automatically to go to the next sequential instruction by adding the length of the current instruction in bytes to the%ripcounter.
- With control flow, we can interfere with
%ripand do things likejmpto another instruction in memory.
jmp
The jmp instruction is an important one.
jmp: The jmp instruction jumps to another instruction in the assembly code (“Unconditional Jump”). The destination can be hardcoded into the instruction (direct jump):
jmp 404f8 <loop+0xb> # jump to instruction at 0x404f8The destination can also be one of the usual operand forms (indirect jump):
jmp *%rax # jump to instruction at address in %raxBut hold on... this is just for unconditional jumps (e.g. while (true). What happens if we want a conditional jump? That is what we will see next.
Conditional jumps
Let us start off with this example:
if (x > y) {
// do something, a
} else {
// do something, b
} In assembly, the conditional takes up two instructions:
- First, we calculate the condition result.
- Then, we jump to a or b based on the condition result.
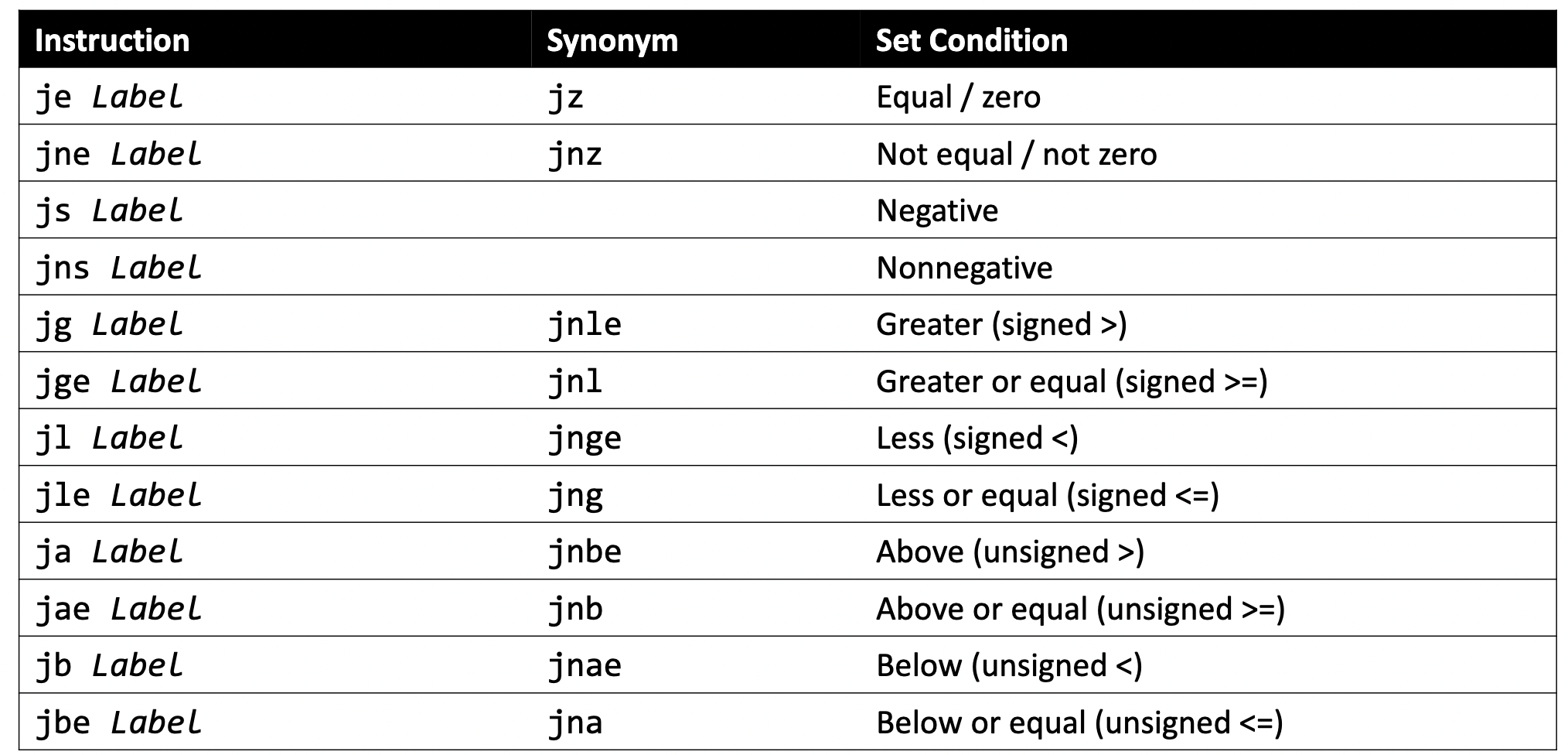
Thus, we have the following common assembly pattern for this:
1. cmp S1, S2 // compare two values
2. je [target] or jne [target] or jl [target] or ... // conditionally jump with if equal, if not equal, and if less than respectively. This is like jmp but it only jumps if the prior condition is true. To achieve this logic, there are many variants of jmp. That is, there are variants of jmp that jump only if certain conditions are true (“Conditional Jump”). The jump location for these must be hardcoded into the instruction (not stored in a register).
Examples:
// Jump if %edi > 2
cmp $2, %edi
jg [target]
// Jump if %edi != 3
cmp $3, %edi
jne [target]
// Jump if %edi == 4
cmp $4, %edi
je [target]
// Jump if %edi <= 1
cmp $1, %edi
jle [target]Condition codes
You might be wondering... how does the computer know what the value of the comparison was if we never stored it in memory to see if the jump statement should be executed? That is,
How does the jump instruction know anything about the compared values in the earlier instruction?
- The answer is in condition codes.
- That is,
cmpcompares via calculation (subtraction) and info is stored in the condition codes.
- Then, conditional jump opcode instructions look at these condition codes to know whether to jump.
These special condition code registers are one bit and store the results of the most recent arithmetic or logical operation.
Most common condition codes (note these are all booleans represented by a 1 or 0):
CF: Carry flag. The most recent operation generated a carry out of the most significant bit. Used to detect overflow for unsigned operations.
ZF: Zero flag. The most recent operation yielded zero.
SF: Sign flag. The most recent operation yielded a negative value.
OF: Overflow flag. The most recent operation caused a two’s-complement overflow-either negative or positive.
So basically, cmp subtracts operand 1 from operand 2 (s2 - s1) and flips the values of the condition codes accordingly.
For example, you could have a string comparison using strcmp and it may return a positive number which the computer will know because SF will be marked as a 0.
Readcmp S1, S2as compareS2toS1by calculatingS2 – S1
The examples above but now with comments explaining how the comparison works:
// Jump if %edi > 2
// calculates %edi – 2
cmp $2, %edi
jg [target]
// Jump if %edi != 3
// calculates %edi – 3
cmp $3, %edi
jne [target]
// Jump if %edi == 4
// calculates %edi – 4
cmp $4, %edi
je [target]
// Jump if %edi <= 1
// calculates %edi – 1
cmp $1, %edi
jle [target]You can parse through the logic yourself to figure out which condition codes are checked for each comparison, but the common ones you could theoretically just remember. Here is the chart where each conditional jump instruction is annotated telling you what condition codes it looks after):
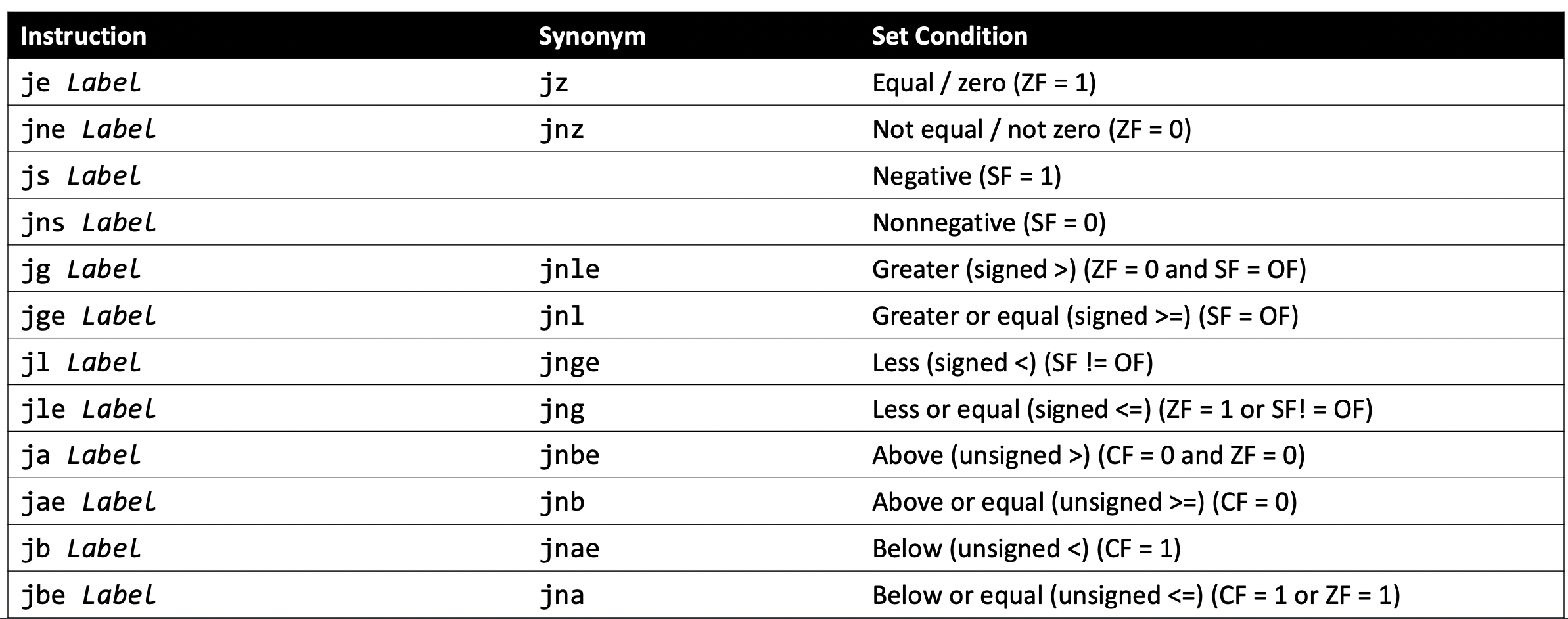
- Note that there are also other instructions which explicitly change condition codes such as
testwhich is like&in C (so it is reallyandbut instead of storing the result in a register, it just sets the condition code(s)).- Actually in fact, all instructions have the potential to change condition codes... except for
lea.
- Actually in fact, all instructions have the potential to change condition codes... except for
If-statements
Let us use our knowledge to fully understand how we can understand things like if-statements in assembly.
- Note that the order of instructions is kind of the opposite as it appears in C. For example, in an if-statement, if the condition is true, we jump to another location in the assembly instruction list which stores the code inside the if-statement. Then, it jumps back to the original position once done. In fact, if the if-statement evaluated to false, then the jump was never taken and you just execute sequentially as normal. Take the following example:

cmp is true, then the jump, je, moves down to a different location then back up. - Ok... but what about more complicated things like if-else, else-if, etc.?
If-else
There is a funky pattern for if-else statements which you should be familiar with. As described above in normal if-statements, if the statement is true, you jump somewhere to perform the content in the if-statement body. However, with if-else, it is kind of in reverse:

First, you compare and if true, you jump to the else body first. If not true, you simply execute the next instruction sequentially which is the if-statement body. Because of the fact that if the compare instruction evaluates to true then you go the else body, the actual comparison is reversed from what is seen in the C code (e.g. if (x > y) is really if (x < y). See lecture for examples.
- Just always remember that you are "jumping" over code that you do not want to execute.
Loops
Now let us talk about loops in assembly.
- Of course, C provides several looping constructs—namely, do-while, while, and for. No corresponding instructions exist in machine code. Instead, combinations of conditional tests and jumps are used to implement the effect of loops.
Two common patterns we see:

Another less common pattern (often seen in earlier versions of GCC):

For loops
For loops actually are represented in a very similar manner to while loops. This is because you can actually represent a for loop using a while loop:

Thus, we only need to add two instructions to our general pseudocode for assembly:

Assembly: Function Calls and the Runtime Stack
We will wrap up our discussion of assembly with function calls. This undoubtedly might be the hardest part so pay close attention to all the little details.
We wish to:
- Learn how assembly calls functions and manages stack frames.
- Learn the rules of register use when calling functions.
Revisiting %rip
- We mentioned previously how
%rippoints to the next instruction to execute. Let us dive deeper.
- Let's say you have a
jmp. In the actual machine code binary representation, the binary does not actually store the address you should jump to. Instead it just stores the byte offset. That is, it says how many bytes you should move further down the assembly line to get to the next instruction to execute. That is,jmpchanges the value of%rip.
Calling functions
We first must understand the terms caller and caller.
To call functions in assembly, we need to do a couple things:
- Pass Control –
%ripmust be adjusted to execute the callee’s instructions, and then resume the caller’s instructions afterwards.
- Pass Data – we must pass any parameters and receive any return value.
- Manage Memory – we must handle any space needs of the callee on the stack.
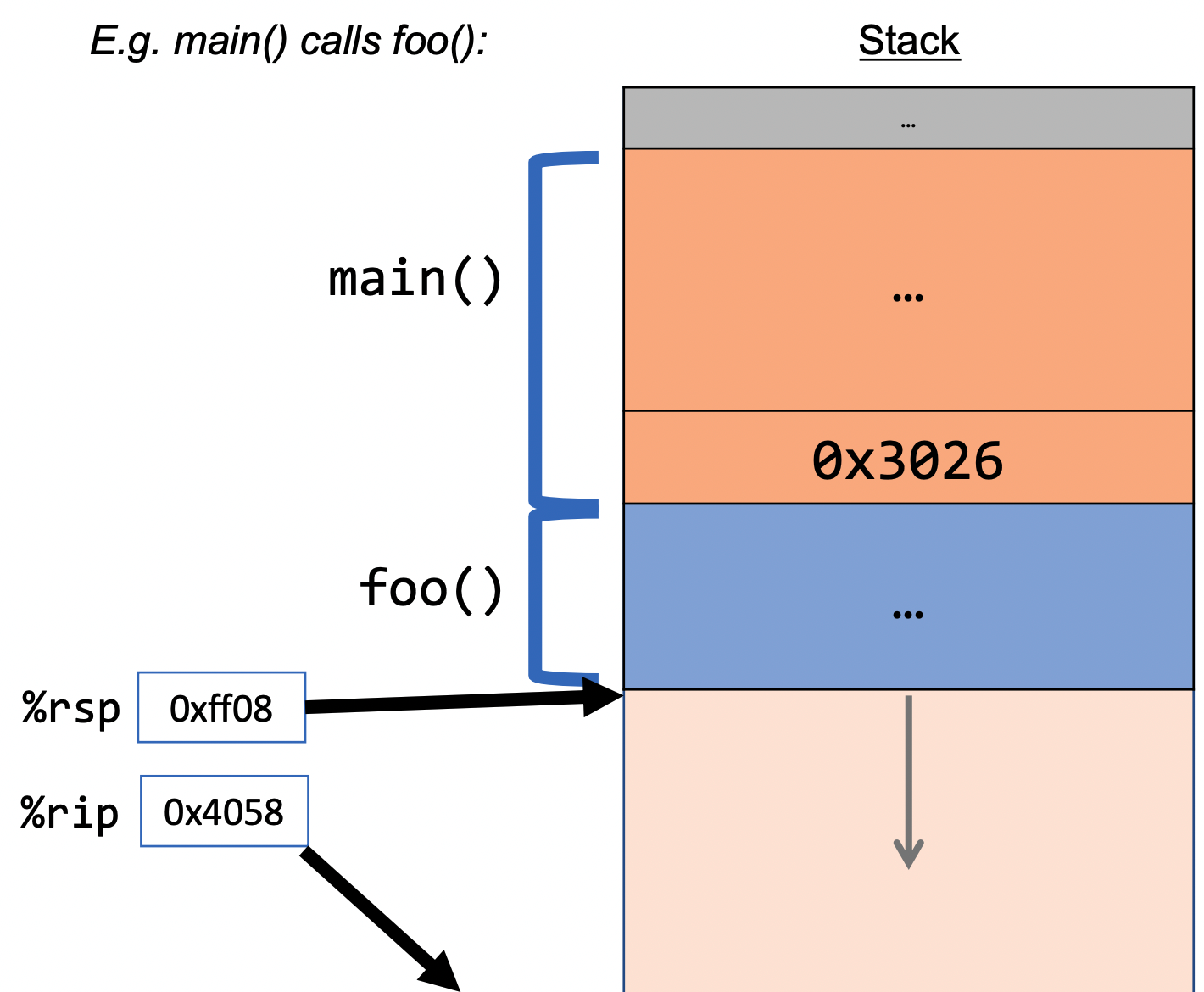
Remember that function calls work by adjusting the stack and each stack frame represents a function call. So does assembly interact with the stack? Via a special register:
%rsp is a special register that stores the address of the current “top” of the
stack (the bottom in our diagrams, since the stack grows downwards).Examples:
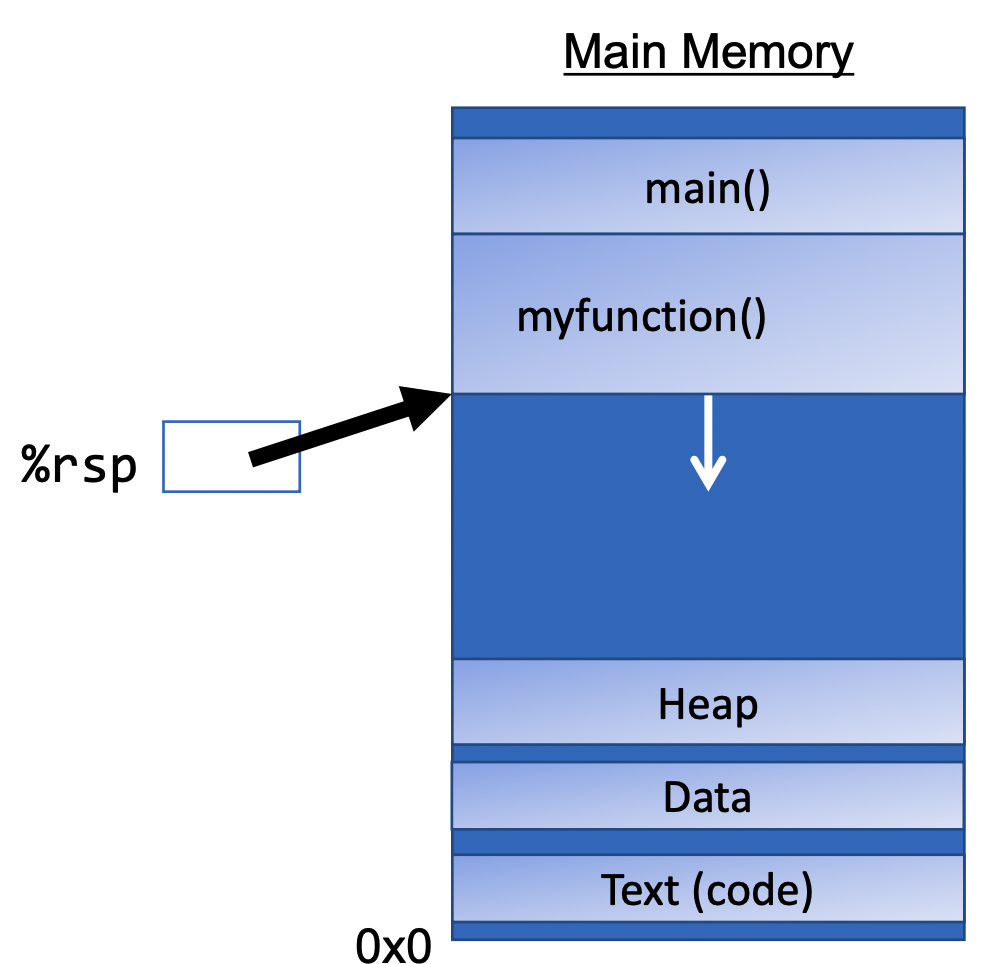
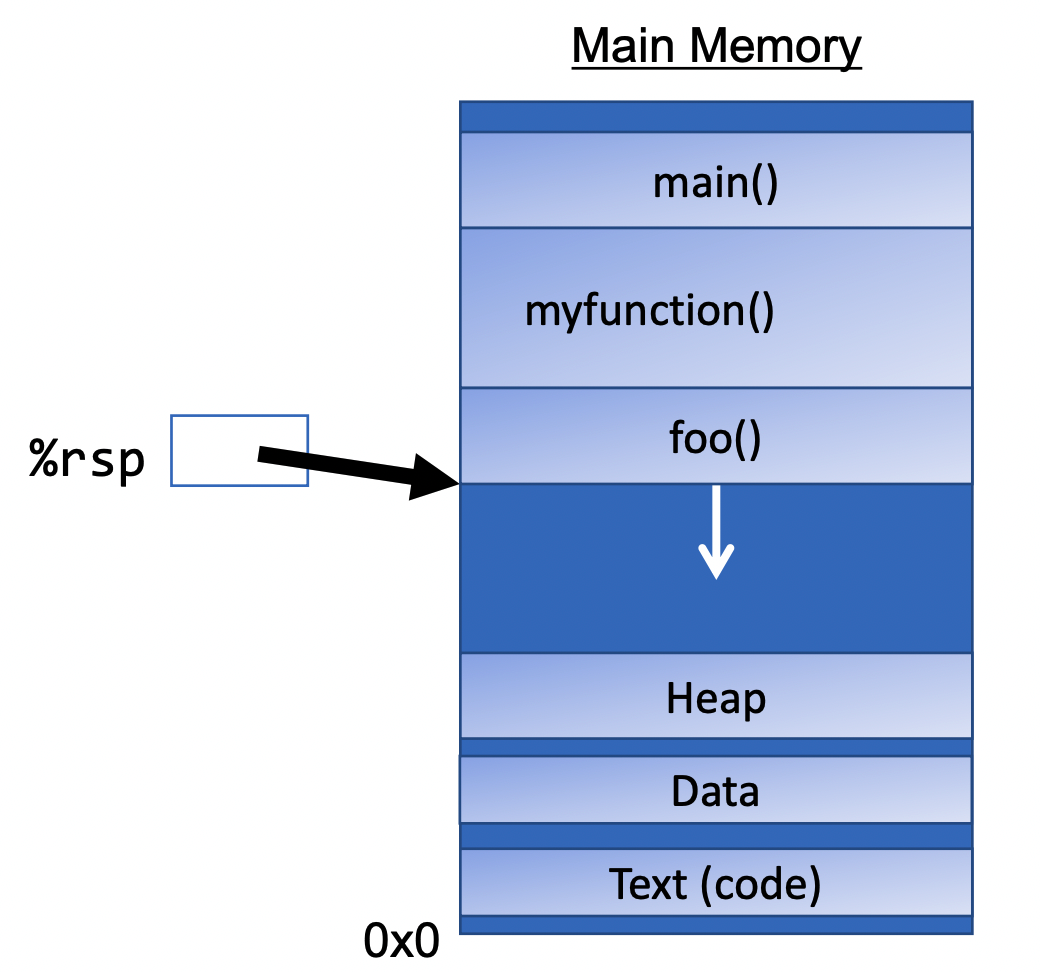
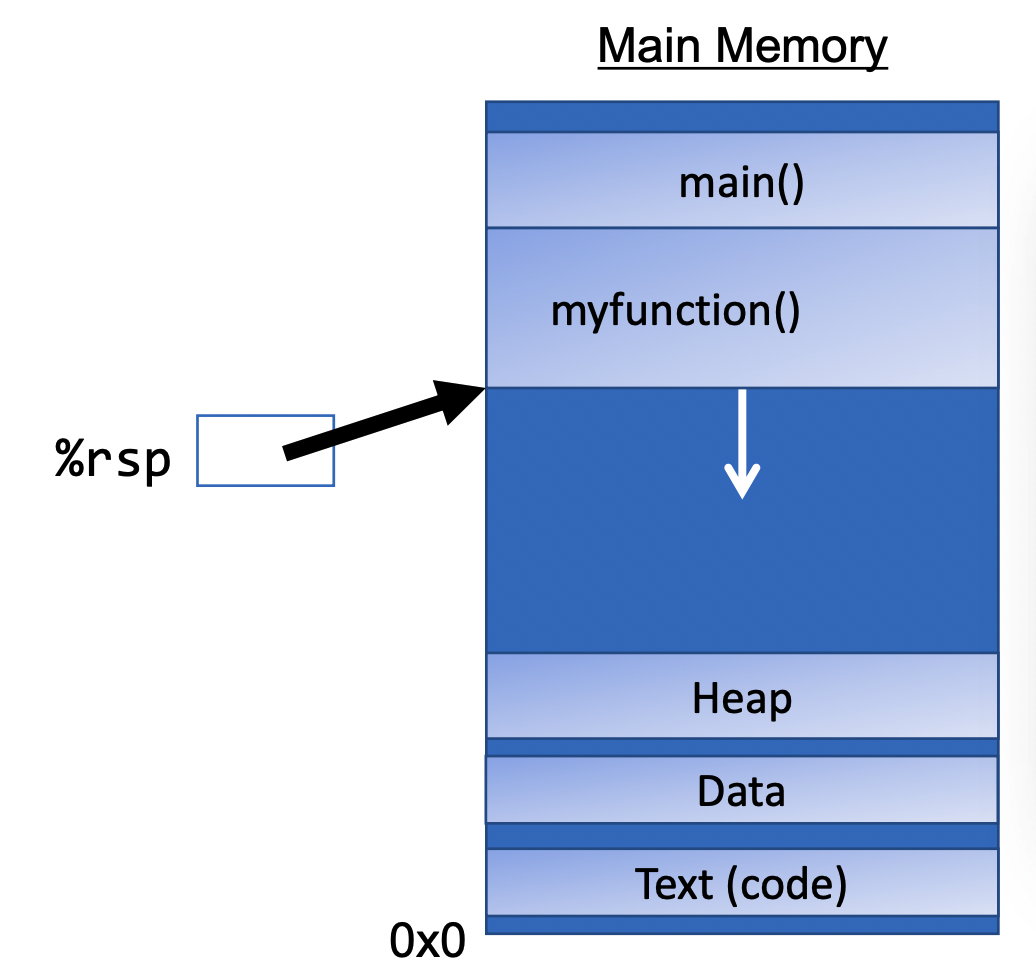
%rsp must point to the same place before a function is called and after that
function returns, since stack frames go away when a function finishesInteracting with the stack
push instruction pushes the data at the specified source onto the top of
the stack, adjusting %rsp accordingly. - Remember that the stack grows downwards to what push does is make some room on the top of the stack by decrementing
%rsp.

pop instruction pops the topmost data from the stack and stores it in the
specified destination, adjusting %rsp accordingly. - Since stack grows downwards, we are shrinking the stack by adding 8 bytes to
%rsp.

- Note that
popdoes not remove data/zero out data it is popping.
Passing control
We need to remember where we left off in a certain function when we call another function (i.e. what instruction to execute next after the callee function is done executing). But the problem is %rip will be pointing at different things because the callee will be updating it. So we bookmark our spot by appending it to the top of the stack before we move to the instructions for the callee. Then, once we are done, we take the bookmarked value from the top of the stack and store it back into %rip. Then, we adjust %rsp.
Example (5 total sequences):
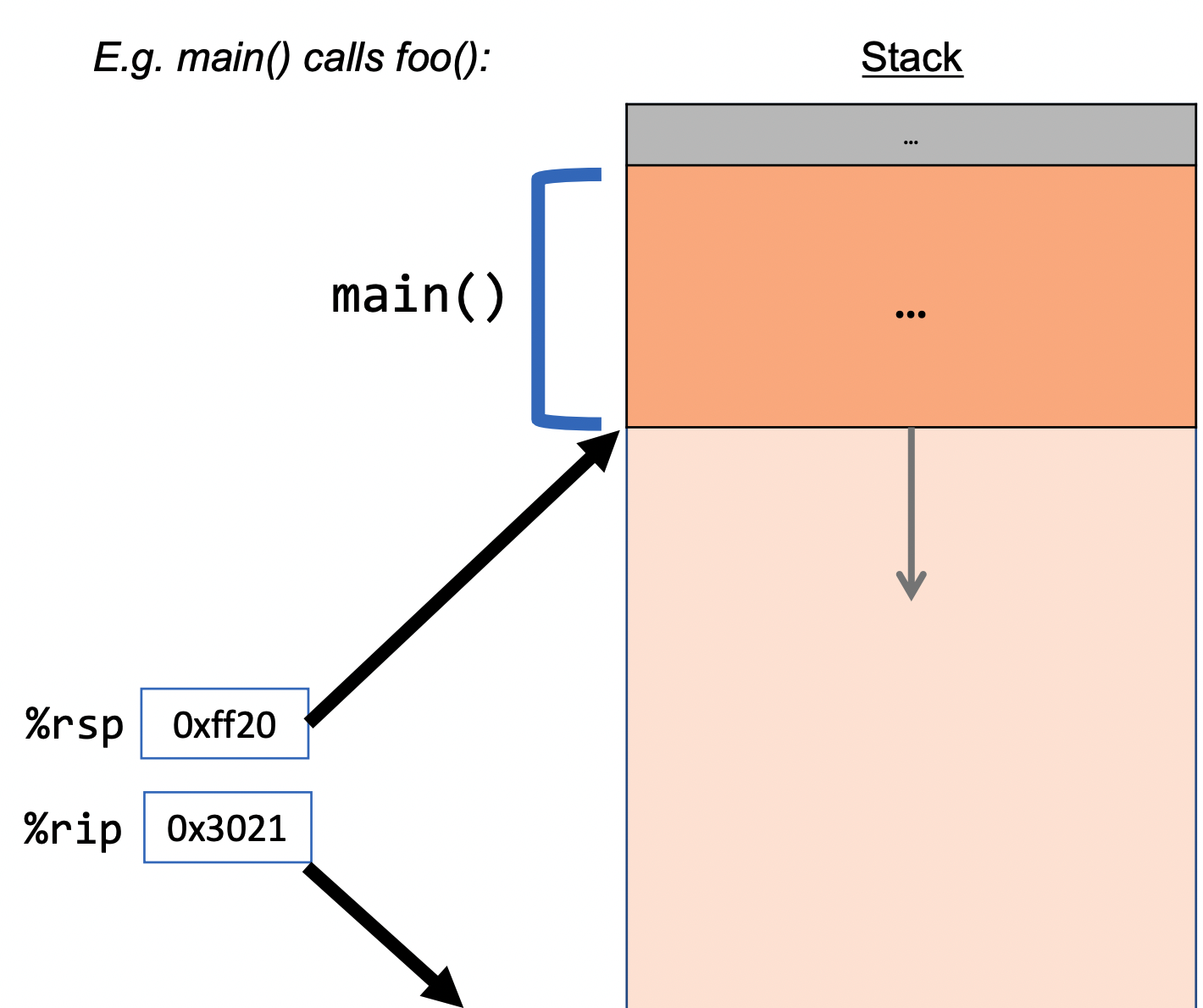
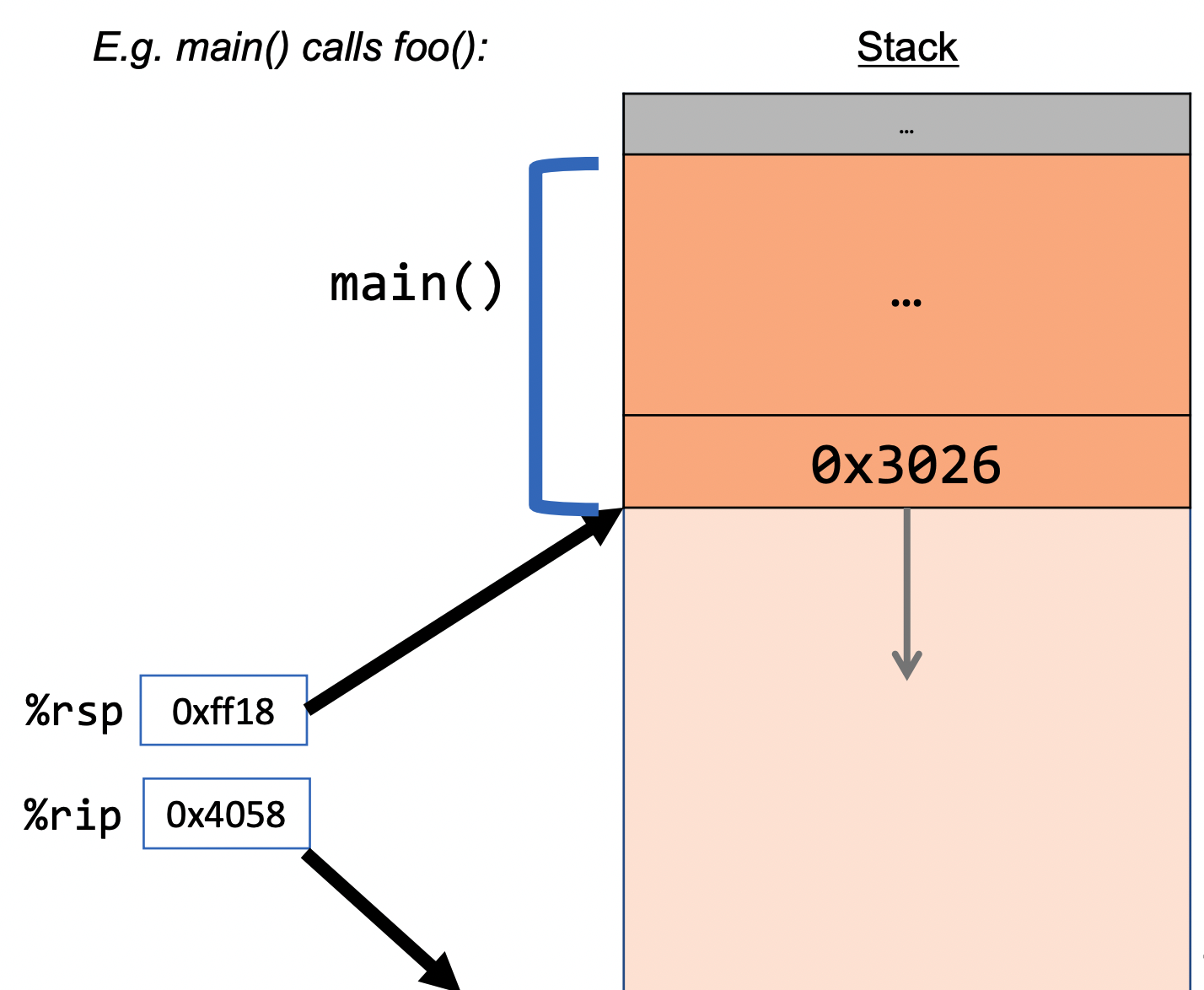
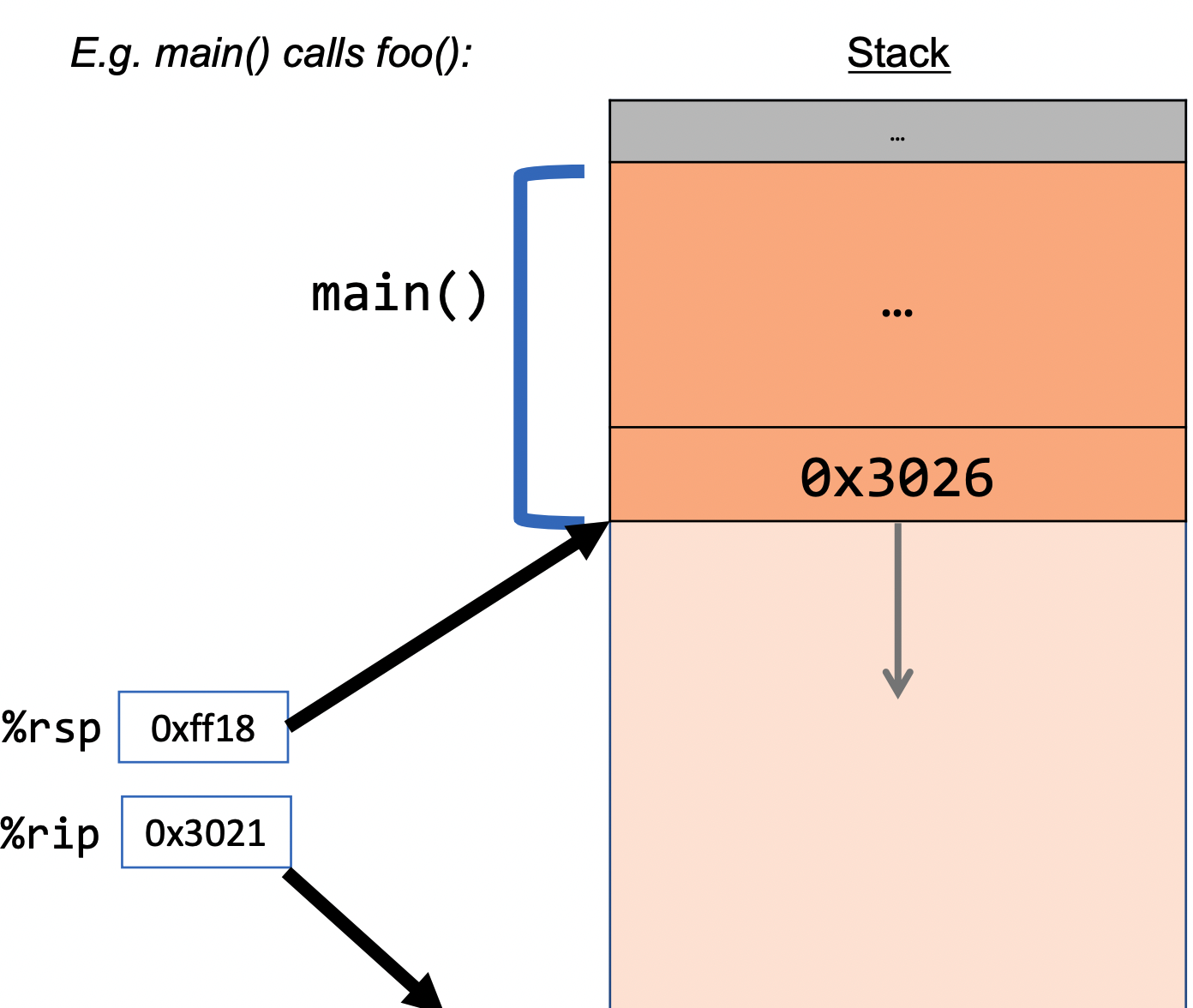
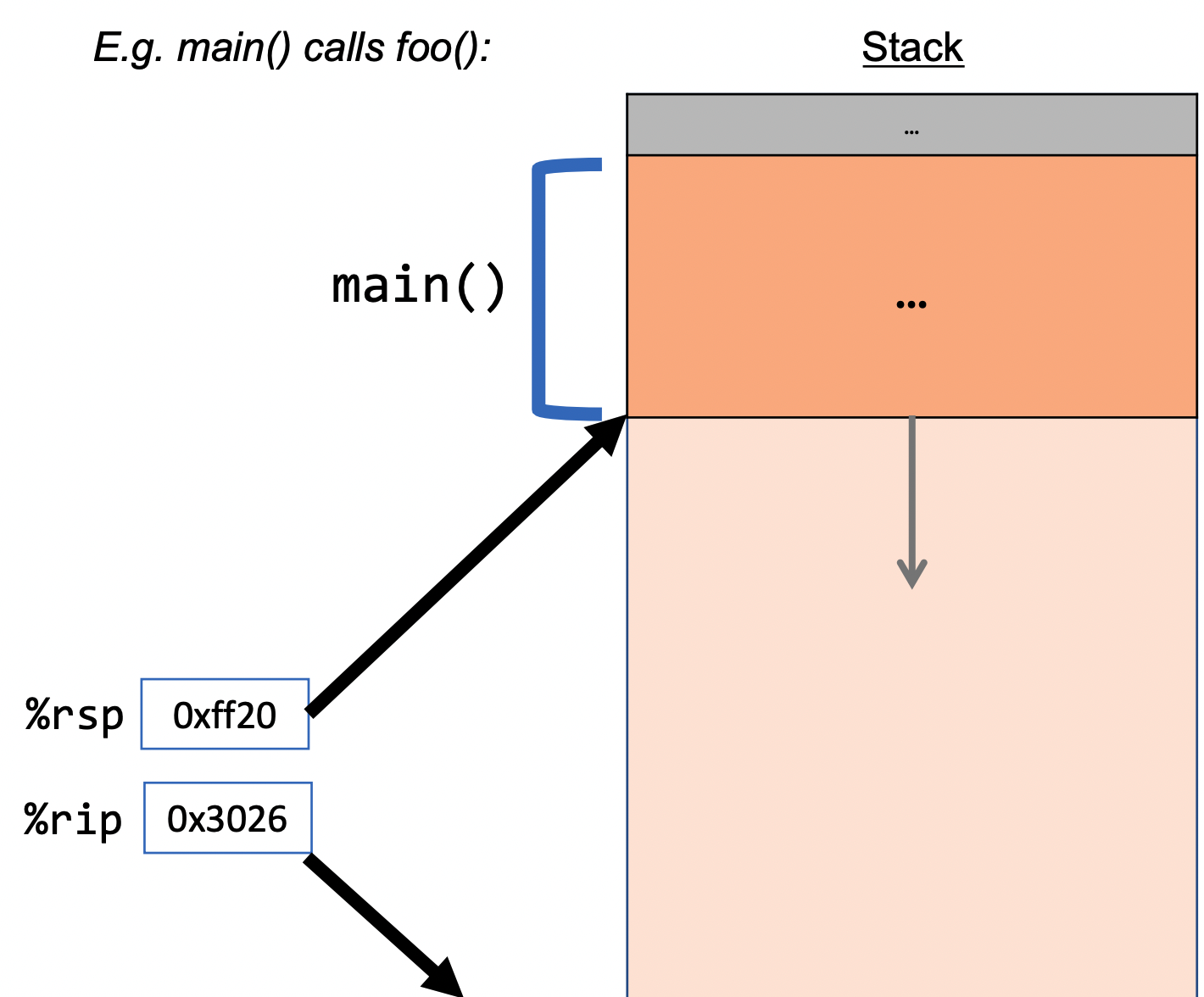
But how does this happen in assembly? Via these new instructions:
call: instruction that pushes the address of the instruction immediately following the call instruction onto the stack and sets %rip to point to the beginning of the function (its instructions in assembly that is) specified by the operand. - In the diagram above,
calldoes the first 3 steps.
The ret instruction does the opposite:
ret: instruction that pops the instruction address from the top of the stack (i.e. the one the was appended by call and stores it in
%rip. Passing data
- Recall that several registers are dedicated for holding argument values for parameters.
That is, there are special registers that store parameters and the return value.
- However, we must manually put these values into the corresponding registers.
To call a function, we must put any parameters we are passing into the correct registers. (%rdi,%rsi,%rdx,%rcx,%r8,%r9, in that order).
- Then, the callee can expect the parameters to be stored in these registers.
- Note: if there are more than 6 parameters, then the next ones are stored on the stack.
- The callee should put the return value into
%rax.
%rax: stores the return value of the callee. Return value must manually be placed into %rax. Some common themes you will see in the assembly generated:
- Parameters are added to registers. Note that this is generally done in reverse order.
A lot of prepwork to call a function before the function is actually called.
Local storage and memory management
We have not really talked much about things like local variables and how that works. In actuality, we store as many local variables into registers as we can and then after those fill up, we start allocating the data to the stack. There are also three times in which we just go straight to the stack (i.e. don't even attempt to store into register):
- Arrays
- Can't do things like addressing and pointer arithmetic on the registers.
- Simply no more registers available
&operator is used. Registers don't have corresponding addresses.
As an aside, even without function calls, we might need to adjust the stack pointer before adding things like local variables.
Register restrictions
- There is only one copy of registers for all programs and functions. Thus...
Problem: what iffuncAis building up a value in register%r10, and calls funcB in the middle, which also has instructions that modify%r10? funcA’s value will be overwritten!
Thus, we must make some rules of the road to which the instructions must abide by when moving things in and out of registers.
Solution: make some “rules of the road” that callers and callees must follow when using registers so they do not interfere with one another.