Lecture 14: Managing the Heap
Table of contents:
We will discuss how malloc/realloc/free work–specifically their implementation. Pulls together all of course topics thus far.
Learning goals:
- Learn the restrictions, goals, and assumptions of a heap allocator.
- Understand the conflicting goals of these two things called utilization (i.e. memory efficiency) and throughput (i.e. time efficiency).
- Understand different heap allocator implementations.
1. The heap so far
- We have used the heap as a client. When we run a program, a “loader”, from the operating system, loads the program into main memory. Things like:
- Creates new process
- sets up address spaces
- array blocks
- Read executable file, load assembly instructions, load libraries, etc.
- But another thing that the loader does is setup the stack and reserve stack space for the program.
init %rsp
- But we do not initialize the heap until first use (i.e. first
malloccall).
- The stack management involves really just moving
%rsparound. Everything is managed for us automatically for things like function calls, etc.
- We also have the heap which is manual management. Heap memory persists throughout the program (i.e. across function calls) until caller calls
freeon that memory.- The way this works is by calling the C standard library functions
malloc,realloc, andfree. But we have only seen these from a client perspective. In the following lectures and assignments, we will learn how to understand the implementations and inner workings of such functions.
- The way this works is by calling the C standard library functions
Our role so far: client
- We have used
malloc,realloc, andfree. Now our role will change.
It is vital that you recall what these functions do (see the man page here):
malloc: a function that allocatessizebytes on the heap and returns a pointer to the starting address of the allocated memory.
void *malloc(size_t size); realloc: a function that changes the size of the memory block pointed to byptrtosizebytes.
void *realloc(void *ptr, size_t size);free: a function that frees the memory space pointed to byptr(must be heap memory that is being pointed to).
void free(void *ptr);
Our new role: heap allocator
- We will manage the requests (i.e. the calling of the standard library functions) on the heap.
By “requests” we mean calls to malloc, realloc, and free.
But what is the heap?
- On initialization (i.e. the first call to
malloc), a heap allocator is provided the starting address and size of the heap (the block of memory).
Imagine that this diagram is the heap:

A heap allocator implementation must manage this block memory as clients request or no longer need parts of it.
2. Requirements and goals of a heap allocator
Let us dive into some details.
Requirements
Some core requirements that a heap allocator must adhere too:
- Handle arbitrary request sequences of allocations and frees.
- The HA cannot assume anything about the order of allocation and free requests. Even more, it cannot assume that every allocation is accompanied by a matching
freerequest.
- The HA cannot assume anything about the order of allocation and free requests. Even more, it cannot assume that every allocation is accompanied by a matching
- Must keep track/mark which memory slots are already allocated and which are available.
- Decide which memory block to provide to fulfill an allocation request.
- This is hugely important and spans most of what we will study (e.g. should we priotize memory space or time?).
- Immediately respond to requests without delay.
- i.e. no waiting to “batch” requests. No reordering to make more efficient.
- Return addresses for allocation requests must be 8-byte aligned (i.e. each address given is a multiple of 8).
- One reason for this is for efficiency (for things like search).
- Another very important reason is the bit pattern for numbers that are multiples of 8. This is important for implementing the implicit allocator which we introduce later.
- To confirm your understanding, recall that calls to the C standard library functions for allocation requests return an address (i.e. pointer).
Goals
Two core goals which are negatively correlated.
- Goal 1: maximize throughput which is the number of requests completed per unit time (i.e. time efficiency).
- Goal 2: maximize memory utilization, or how efficiently we make use of the limited heap memory we have to satisfy requests (i.e. memory efficiency).
- They are negatively correlated in that the goals are somewhat conflicting. For instance, it may take longer to plan out an efficient use of the heap memory (so it would have greater memory efficiency but as a result, suffer in the time efficiency department because it would take some time to plan out the heap meticulously).
- There are also other goals involved which aren’t as important to us (i.e. locality, robustness, ease of implementation).
Fragmentation
The primary cause of poor heap utilization is a phenomenon known as fragmentation which we discuss here.
Let us discuss more about the second goal and some common scenarios people encounter. Say we have the following scenario:
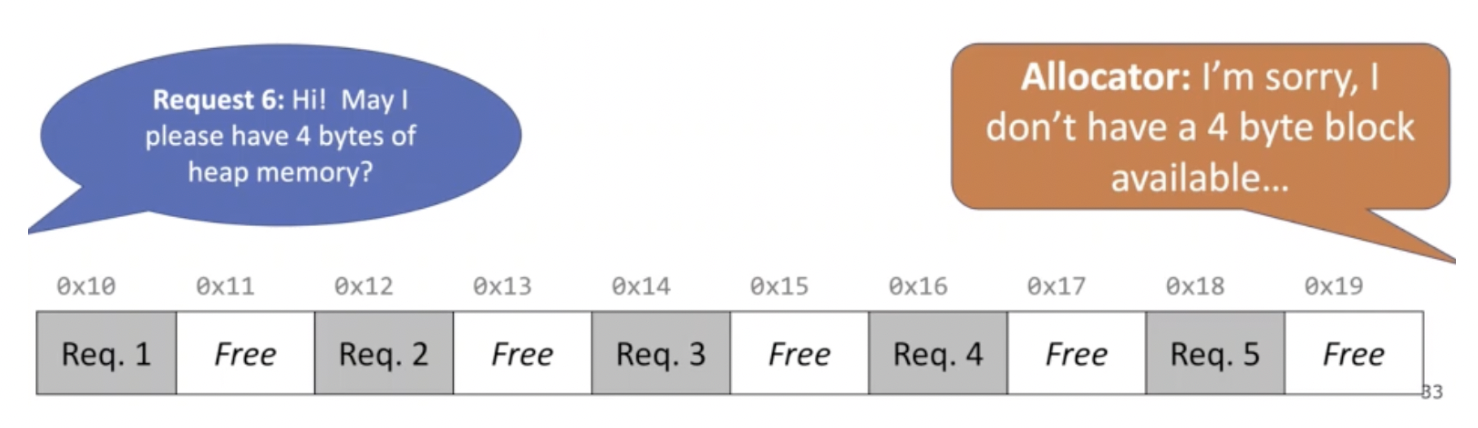
Here, the client is asking for 4 bytes but the allocator does not have a contagious 4 byte block. However, there are more than 4 bytes free… just not contagious. This inefficiency is known as fragmentation which occurs when otherwise unused memory is not available to satisfy allocation requests.
So how do we solve this? If you think about it, in general, we want the the largest (i.e. highest... not largest byte-wise) address used to be as low as possible.
To do this we might want to manually shift the blocks down to make more space. Like so:

But we actually cannot do this. This is because when a client makes an allocation request, the HA returns an address to the block in memory. So shifting a bunch of blocks around will ruin prior addresses given (i.e. incorrect pointers).
We can further divde the problem of fragmentation into two subproblems:
- Internal fragmentation: An allocated block is larger than what is needed (example would be minimum block size which can occur due to the 8 bytes aligned design specification; that is, we may need four bytes but we must start the next sequence of bytes 4 bytes further since we align everything via 8 byte widths).
- External fragmentation: no single available block is large enough to satisfy the request, but there is, in aggregate, enough free memory available (e.g. what we described above).
3. Bump Allocator
Ok... now that we understand the goals and requirements of a heap allocator, we will implement one. There are many different design optimizations one can make when it comes to designing heap allocator implementations (e.g. should we prioritize space or time efficiency?) so indeed, there are many different types of implementations. We will cover three such implementations where the first one is a "baby" implementation with poor design but easy to implement. It is called a bump allocator (which we will abbreviate BA here).
- The design of the BA is inefficient in the memory department because it never reuses memory.
- So it prioritizes throughput (i.e. time efficient).
- So basically, it works like the stack pointer. It keeps track of the end point of the previous
mallocrequest. Every time amallocrequest is made then, it simply gives the block starting at the pointer and then "bumps" the pointer to the end of the allocated block.
freedoes nothing here.
- From the design specified above, it is easy to see that memory is never reused and thus we have poor memory utilization.
- Note: an implementation of the bump allocator is actually provided on the final project spec.
- A bump allocator is an extreme heap allocator –it optimizes only for throughput, not utilization. But we aim to strike a more reasonable balance. We will learn how to do this via the next two heap allocators we introduce. In the mean time, some questions to consider include
- How do we keep track of free blocks?
- How do we choose an appropriate free block in which to place a newly allocated block?
- After we place a newly allocated block in some free block, what do we do with the remainder of the free block?
- What do we do with a block that has just been freed?
4. Implicit Allocator
Looking above, we see the inefficiencies of the bump allocator. We asked questions about things we can potentially do to make our allocator more efficient. We will harness these ideas to build a more efficient allocator called the implicit allocator. Specifically, we will find solutions to the four questions above.
- Basically, the idea is to prefix every "block" (i.e. from a request) with a header stating the payload (content) size and the status (whether that block is free or not).
One downside is that you need to loop through all blocks to find a free block. To only loop through free blocks, we can make a doubly linked list.