Week 7, Lecture 1 - Domain Adaptation
We will cover the domain adaptation problem and algorithms for solving it.
Intro and problem statement
Note: the wikipedia page provides a good problem introduction.
We aim at learning from a source data distribution a well performing model on a different (but related) target data distribution.
Note
Definition 1 Domain shift (aka distributional shift): a change in the data distribution between an algorithm’s training dataset, and a dataset it encounters when deployed. These domain shifts are common in practical applications.
- Like transfer learning, but we operate in the transductive setting rather than inductive. Meaning, we have access to the (unlabeled) target domain data during training.
- Meaning, during training of the og model on the source data, we have unlabeled data samples of the target distribution.
- Question: what happens if we don’t have access to the target domain data? Frame this as a meta-learning problem? Note: Wed’s lecture might cover this.
- Can think of the idea as tasks but with different distributions of \(p(x)\).
- Robustness.
- Examples:
- Tumor detection: trained on data from source hospital, but need to generalize to target hospital data. A distribution shift.
- Can frame this as two separate tasks.
- Land-use classification: source is landsat images of North America… want to deploy to South America landsat images.
- Tumor detection: trained on data from source hospital, but need to generalize to target hospital data. A distribution shift.
Algorithms
Data reweighting
- See empirical risk minimization:
- “The core idea is that we cannot know exactly how well an algorithm will work in practice (the true”risk”) because we don’t know the true distribution of data that the algorithm will work on, but we can instead measure its performance on a known set of training data (the “empirical” risk).”
- Domain adaptation via importance sampling (see slides for the math).
Note
Definition 2 (Importance sampling algorithm):
- Train binary classifier \(c\) (source \(\mid x\) ) to discriminate between source and target data.
- Reweight or resample data \(\mathscr{D}_S\) according to \(\frac{1-c \text { (source } \mid x \text { ) }}{c \text { (source } \mid x)}\).
- Optimize loss \(L\left(f_\theta(x), y\right)\) on reweighted or resampled data.
Note: might be a good idea to model the distance between two similar data points in this (similar).
Key assumption: the source and target distributions need to overlap.
We need
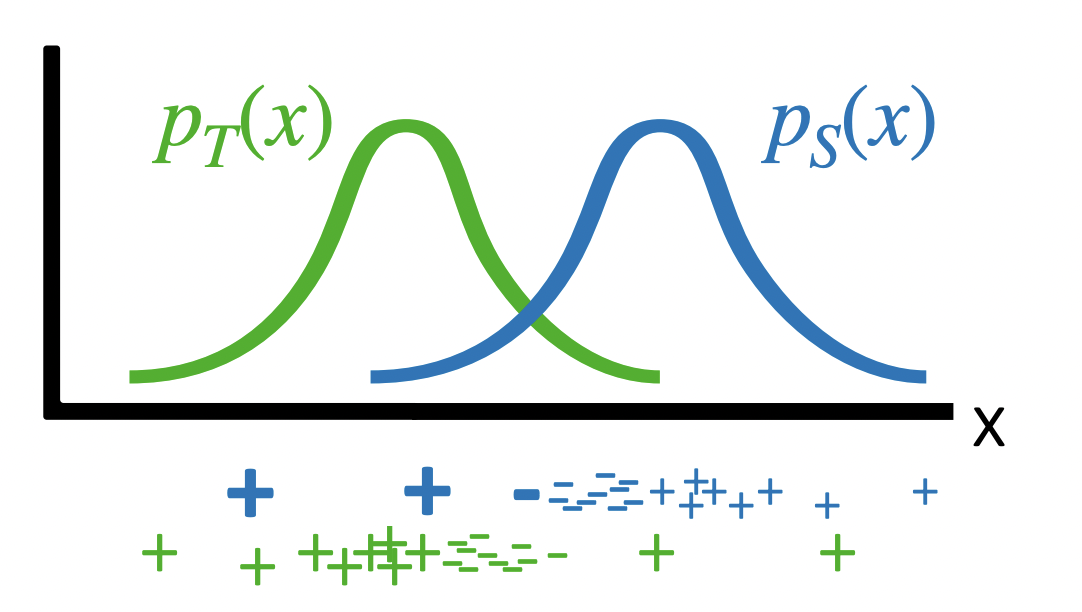
Feature alignment

- MNIST digit-like images but not with blank background.
- Idea: align features (through learning separate encoders and minimizing distance between similar features).
Domain translation
See CycleGAN.
Questions
- What is a distribution \(p(x)\) for the training data? Just the data plotted or the probability of seeing each e.g., class?
- What happens if we don’t have access to the target domain data? Frame this as a meta-learning problem?
- Or is this just a different problem in general?