Week 1, Lecture 1 - Introduction
Date: 9/26/22
- Course content delivered in modules and in lecture (which go over the content from modules in an interactive manner).
- So during lecture, Percy and Dorsa will walk us through the lecture slides from the module page.
Course content
- How can we go from code –> self-driving cars? We need a plan of attack. Here we introduce an AI paradigm consisting of three components:
- Modeling
- Inference
- Learning
- Modeling: i.e., how we can go from a complex problem (e.g., lane shifting) to a nice, mathematical representation from which we can work with.
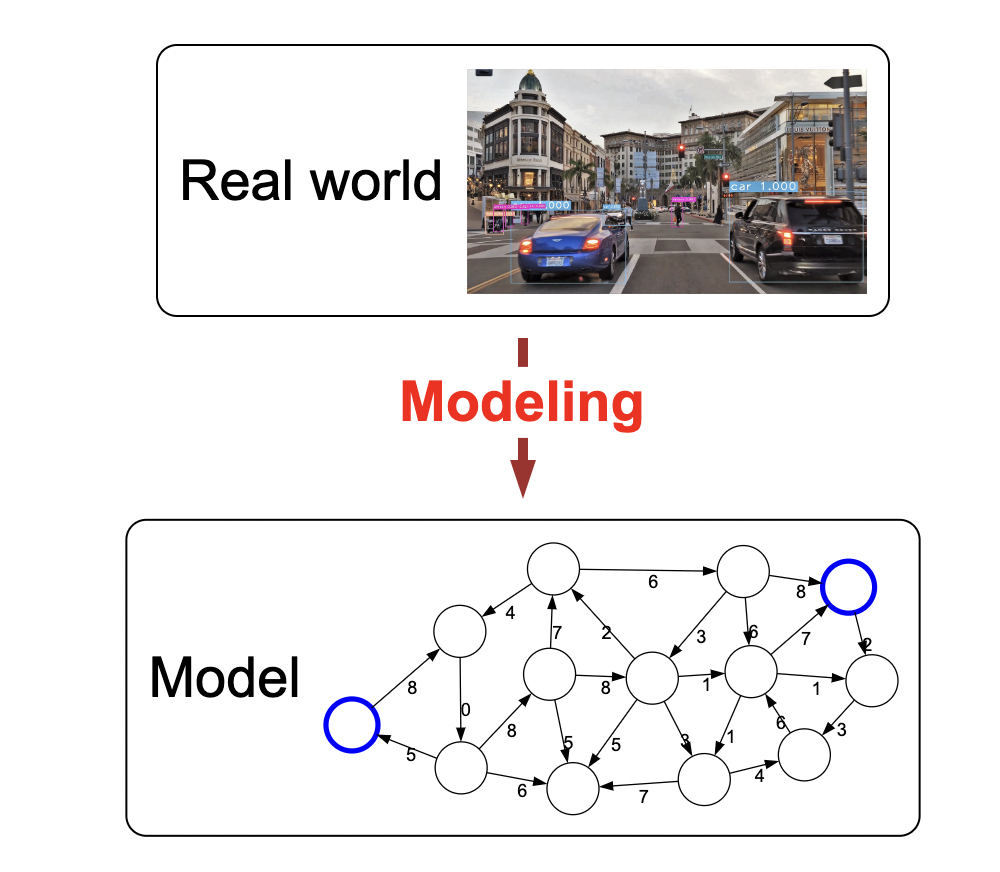
However, modeling is inherently lossy: we lose information due to the complexities of the world. not all of the richness of the real world can be captured, and therefore there is an art of modeling: what does one keep versus ignore?
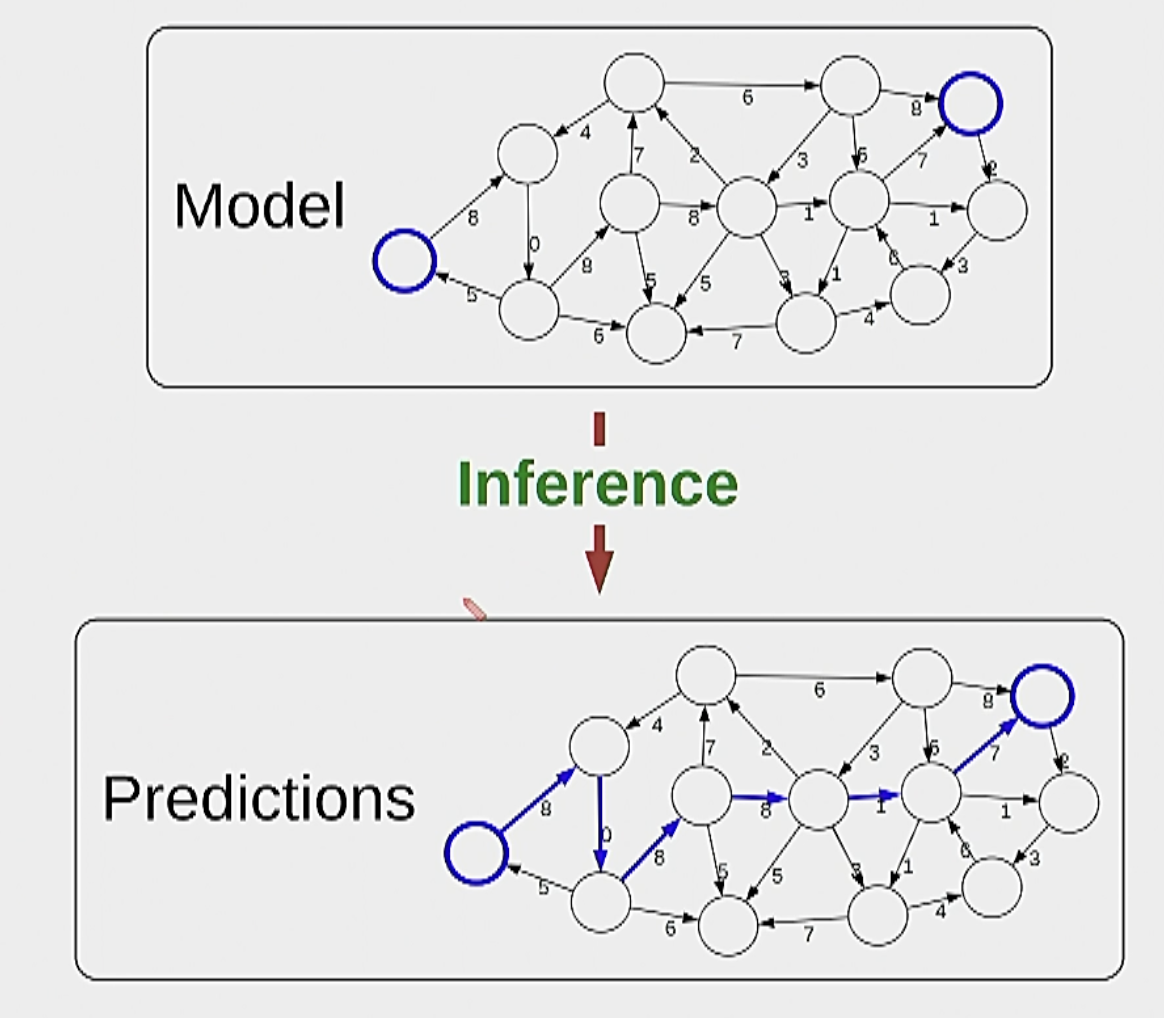
Inference: answer questions with respect to the model. Example given city model: what is the shortest path? Essentially a mathematical excersize where we use algorithms to solve the problem.
- Learning: simplified but real world is complex. Not feasible to write full model. But building a model is very hard to accurately represent the real world. So instead, we can show the computer data and the model is learned implicity through such data.
- i.e., we’ll write down a model architecture (model “family”), you find the edge values by learning.
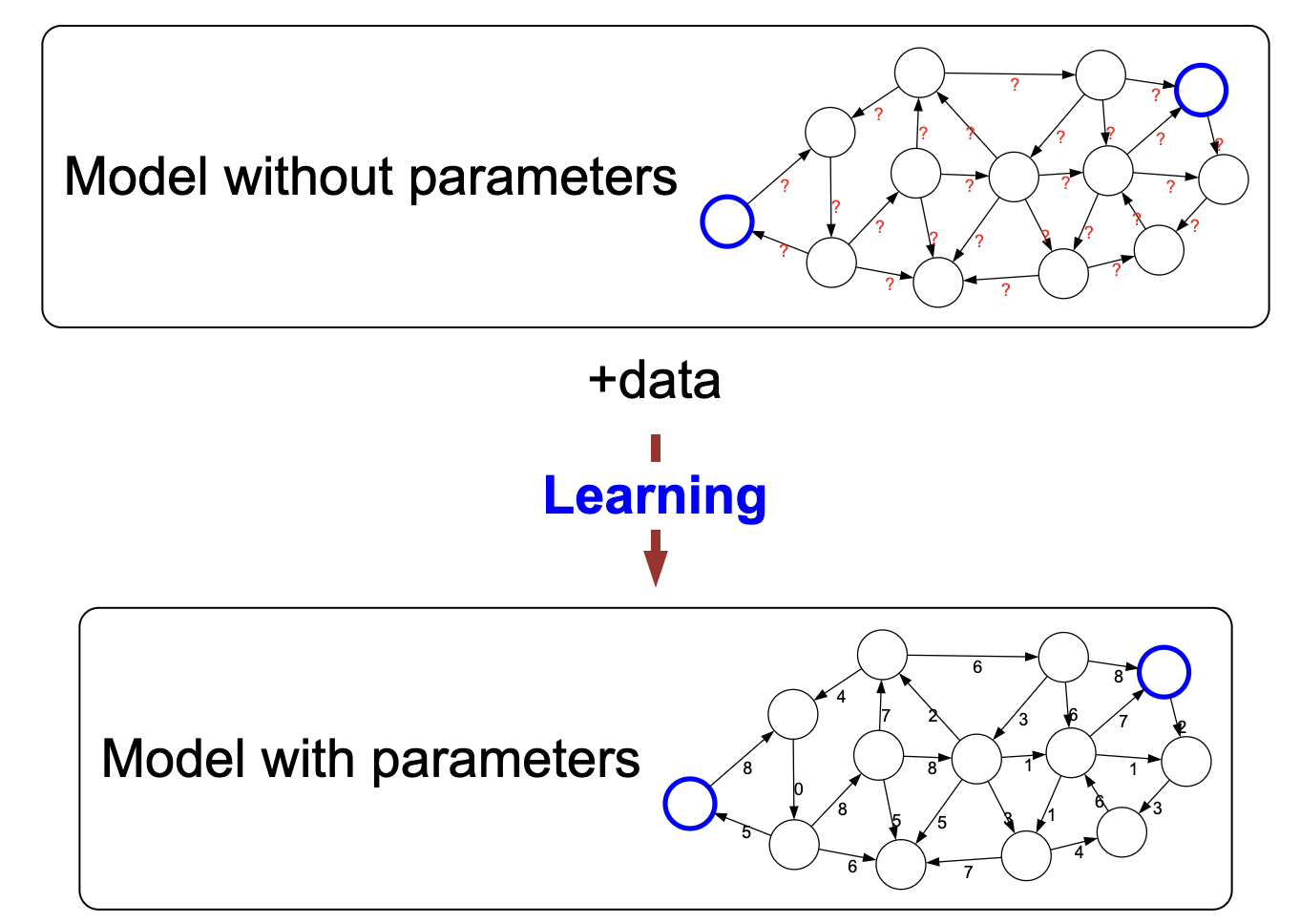
Note: you probably think of neural networks when we talk about modeling. But in actuality, it is much more broad; The idea of learning is not tied to a particular model family (e.g., neural networks). Rather, it is more of a philosophy of how to produce models.
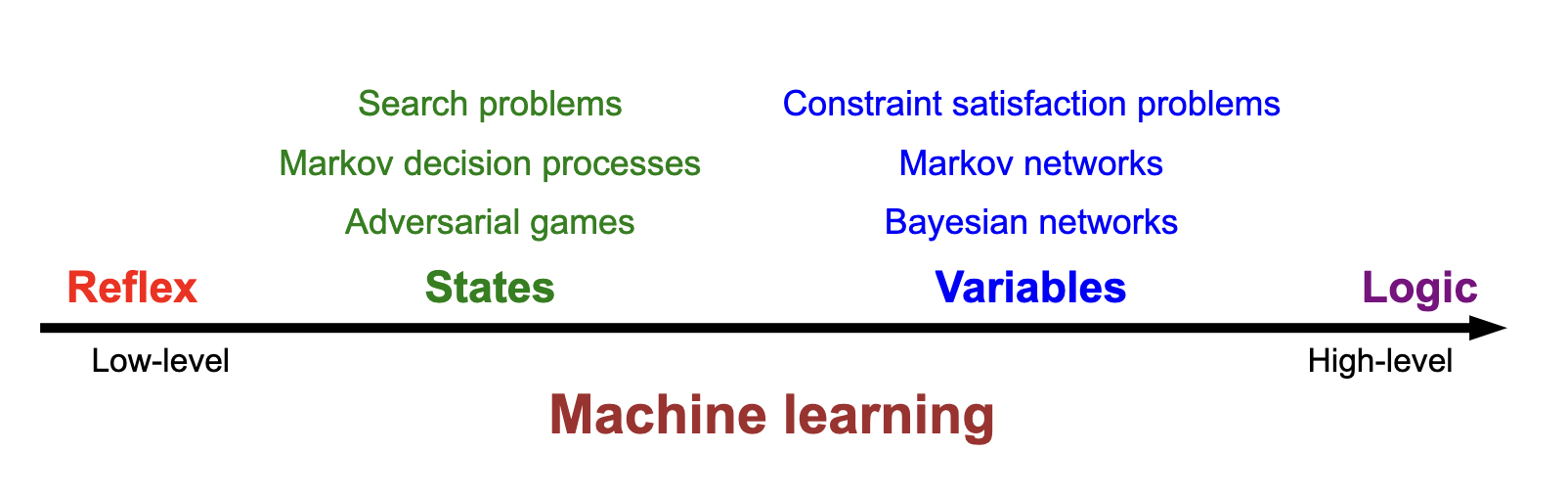
Rest of course: use this paradigm to understand modeling strategies: from low-level to high-level.
Machine learning: data –> model;
State-based model: proceduraly: take next step into next state to “search” for a solution.
Variable-based: assignment: assign bayesian edges in a graph (essentially a PGM).
Course plan chart
AI History
Next module.
- Topics in this course have long and complex history.
- Turing test: define intelligence as a machine that can fool a human.
- Three stories of the birth of AI.
- Birth of AI (1956): John Mcarthy organizes Dartmouth conference during the Summer.
- Proposed challenge to build artificial intelligence with computers. Idea: “Every aspect of learning or any other feature of intelligence can be so precisely described that a machine can be made to simulate it.”
- Produced some good results like Samuel’s chess engine.
- AI summer: expected to be solved in like 10 years.
- But of course: underwelmed… no AGI produced!
- Problems:
- Not enough compute
- Didn’t understand the complexity of the problem (no np-completeness yet!)
- 1. Symbolic AI: Knowledge-based systems (1970s+):
- Idea is to encode explicit domain knowledge in the form of rules:
if [premises] then [conclusion]- Commercial success: medical prediction systems
- Solved limited compute problem
- But world is too complex to model completely with this system.
- Idea is to encode explicit domain knowledge in the form of rules:
- 2. Neural AI: Neural models (1943, 1980’s):
- Mcullugh and Pitts: made mathematical model of neurons. What can it learn?
- Note: these two were Psychologists well before the age of computing: no intention to build AGI.
- Lots of advances until in 1969 Minsky proved that XOR was not solvable by linear NN’s. Killed NN’s for the timing being.
- However, field picked back up again with the rise of connectionism (explaining cognitive phenominoms using neural networks).
- 1980: Fukushima’s neocognition CNN architecture.
- 1986: Hinton’s backprop.
- 1989: Lecun applies backprop learning to Fukushima’s CNN architecture.
- Didn’t really pick up speed until 2000s and 2010s when compute (GPUs) came into fruition and networks could be made “deep”er.
- AlexNet moment!
- Mcullugh and Pitts: made mathematical model of neurons. What can it learn?
- 3. Statistical modeling:
- Bayesian networks, SVM’s, etc.
- Provide theory
- Goes back to Gauss (before AI)
Next module…
Ethics and responsibility
- High-level principle: ensure AI is developed to benefit and not harm society.
- However, it is tough to operationalize these principles in the real world.
- Two axes: intent vs. impact.

- Levels of abstraction so it can get quite complex to see what is right/wrong.
- Downstream impact.
- Accidents:
- Good intent, bad results
- Comes from gap between model and real-world. We lossy it down to the model and then deploy lossy version in real-world. Lossed information can cause problems!
- “Misalignment between real-world objective and system’s objective.”
- Optimize wrong objective function
- e.g., facebook echo chamber: want good user feeedback but can cause political isolation.
- Fairness: performance disparities between different groups.
- Robustness: spurious correlations
- Example: train classifier for collapsed lung. But all collapsed lung x-ray usually has some chest drain device so the model is really just learning to find the chest-drain rather than a pathological identifier.
- Security: adversaries (sticker on stop sign for autonomous driving).
- Good intent, bad results
- Think about the task setup: e.g., don’t make gender classification algorithm.
- Feedback loops: bad algorithm paradigms (as explained above), bad data make for a bad loop.
- Data is of course controversial. Dataset biases, imbalanced classes, legal battles over copyright ownership. Labour problems for labeling data.
So what do we do? - Transparency: document uses, model, etc. - e.g., model cards - Choosing right problems
Summary:
